
To fall or not to fall in the right art unit
Sometimes, some art units are better than the others. Or to be more specific, sometimes, some art units are to be avoided.
In order to do so, you have to:
- Know if you’re at risk of falling into those needs to be avoided art units
- Establish a strategy to avoid those art units
This post will discuss only about the first item, i.e. establishing a prediction of falling in a specific art unit.
Within IPSTAT, we applied to Art unit prediction the semantic proximity used in Questel’s semantic search. In our experience, it had several advantages:
- The semantic proximity is concept-based and not language-based. Which means that it can be used on a Japanese abstract or on Spanish claims and will get some perfectly valid results
- Semantic proximity is document based, which means that I can get the X closest documents and estimate the probability of falling in a specific art unit based on the art unit of the X closest documents.
- Most importantly, it works with any text, this approach doesn’t need to be a published patent to work. It can work whatever the text and whatever the part of the patent that we want to feed the semantic engine on.
In this post, we wanted to give some calculated evidence about the validity of this approach as well as discuss the interest of using abstract, claims or key information (Object, advantages and Independent claims)
In order to validate our approach, we took patents that were already assigned an art unit and launch our tool to see if we could have guessed the art unit only based on:
- Their abstract
- Their claims
- A concatenation of their key information (Object, advantages and independent claims).
We then took the three most probable art units and their associated probability in order to analyse two information:
- The sum of the probability associated with the three first guesses, I.e. the « certainty » that we associate with those three guesses
- A success or failure check that the correct art unit and correct group art unit was within the three first guesses
Key findings
Using the abstract, we were successful in finding the group art unit 82% of the time and the exact specific art unit within three guesses 40% of the time. We map almost perfectly the certainty associated with our guess with the probability of findings.
In other words, if we associate a probability of 70% to being assigned art unit 1615, we will be correct 70% of the time, thus validating this approach as long as each art unit in mapped with a certainty probability.
The semantic analysis of the other part of the patent (claims, independent claims, description, key information) versus the abstract doesn’t improve significantly our prediction percentage.
Using a non-English text doesn’t impair (nor improve) the prediction.
Checking the validity of the estimation percent of specific art unit
By analyzing the abstract, we extract the concepts and analyse a proximity with a specific art unit.
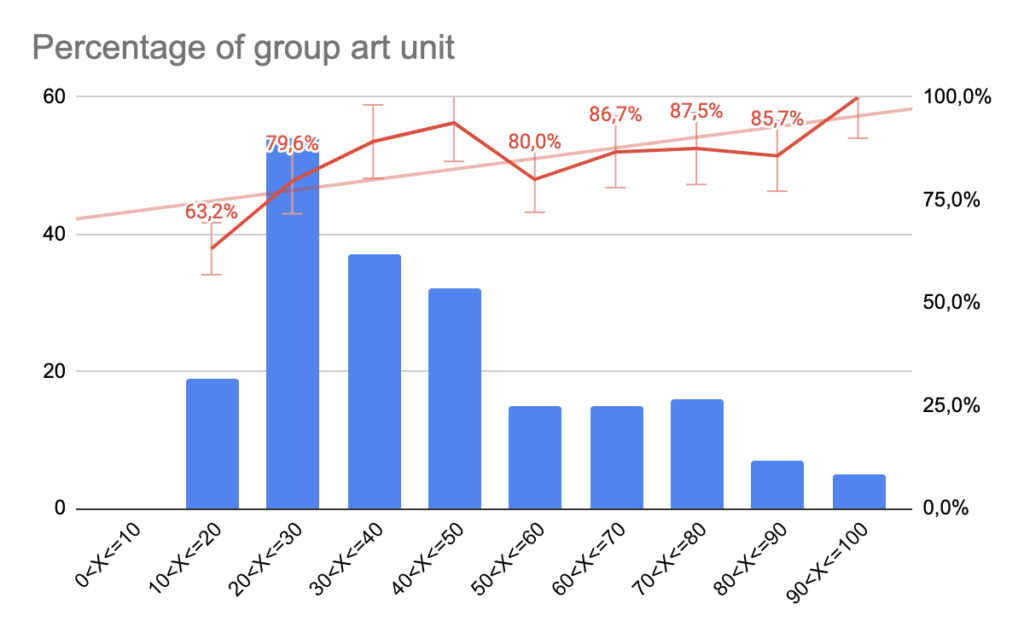
Some text are very generic and the described concepts are widely shared within an important number of art units. Using those type of text will result in having some very small percentage of chance of being assigned the correct specific art unit but will at 80% predict the correct group.
There is a strict correlation between displayed percentage and found percentage.
The percentage of correct art unit follows very precisely the percentage, i.e. if we inform that the art unit has a 70% chance of being assigned, we will be correct 70% of the time. This is a very important point for us as it validates concept-based semantic approach of art unit prediction.
In average a concept-based art unit prediction will have a 40% predicted percentage of getting the specific art unit if we use the abstract.
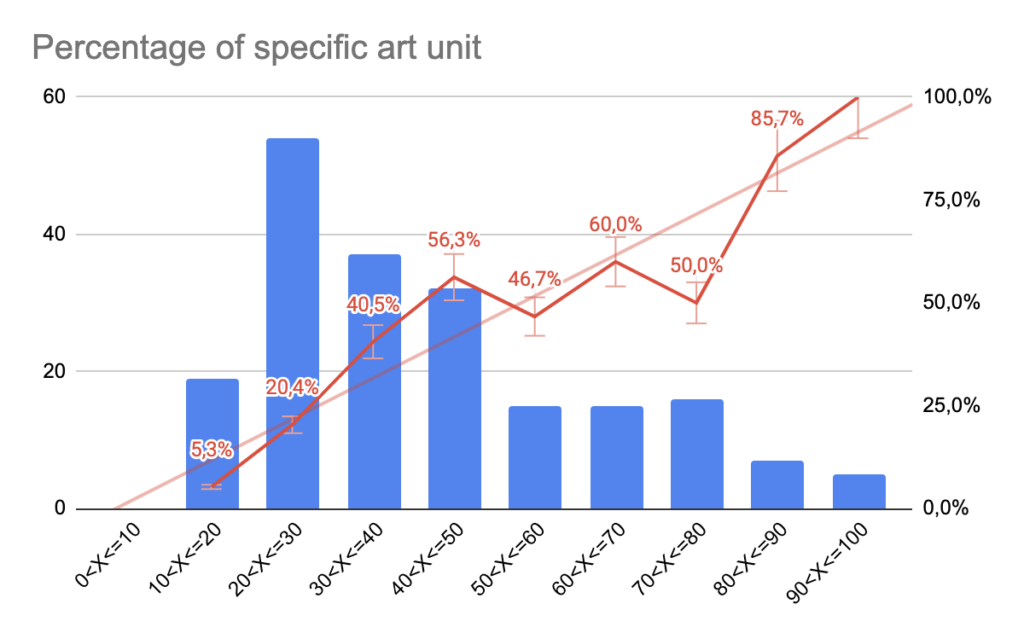
For generic text where we estimate between 10 and 40% of chance of specific art unit, the group art unit is correctly inferred 80% of the time.
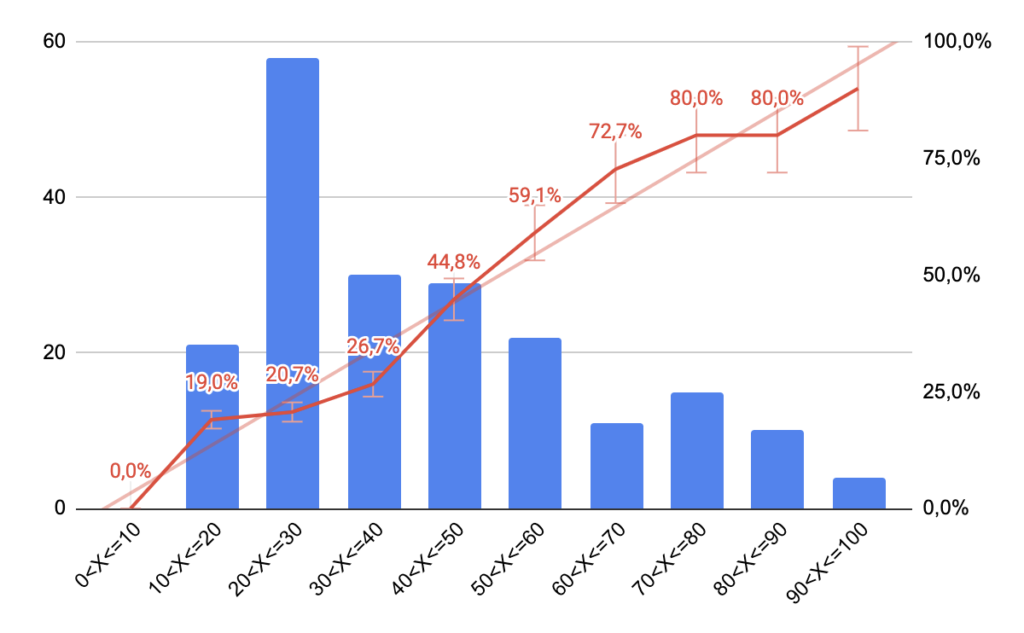
Using Claims, independent claims, Object and Advantages
Using claims instead of abstract will have almost identical results, i.e. a strict correlation between our estimated percentage and actual correct guess. Abstracts with concepts widely shared among an important number of art units will also have claims with concepts widely shared among an important number of art units making it unnecessary to mix both approaches.
Testing other parts of the patents: description, independent claims, object of the invention and advantages brought us less interesting results.
The only approach bringing an added value was to concatenate independent claims, object and advantages. This approach brought us more differentiation for patents with generic concepts bringing additional accuracy but also in a significant number of times complete misconception.
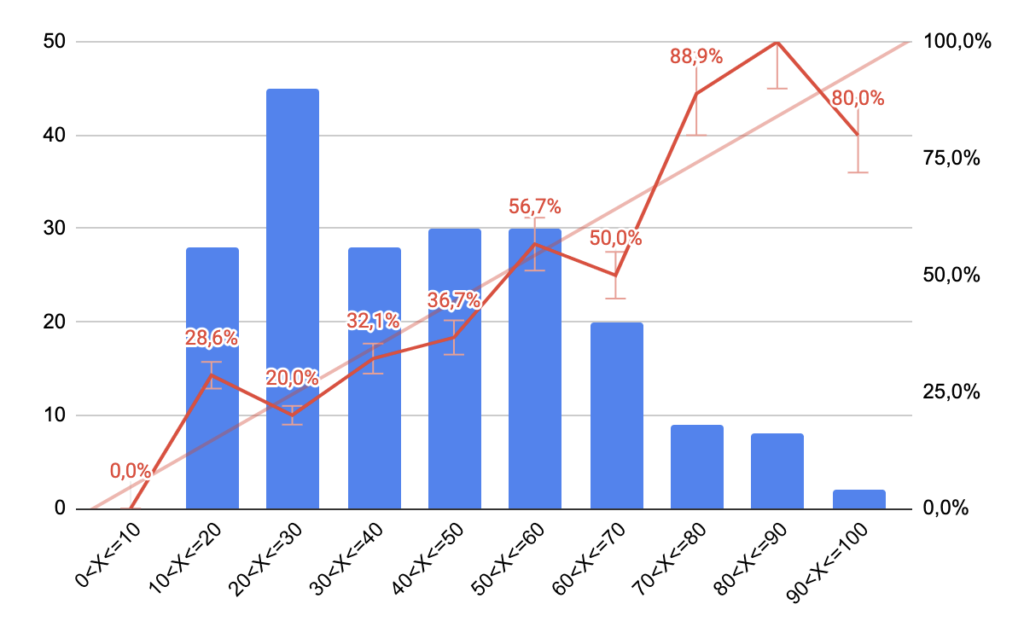
If this approach could be interesting for published US applications, it proves difficult to apply on foreign priority texts and for unpublished application. The advantages do not outbalance those inconveniences and it seems more relevant to concentrate our approach on the abstract-based semantic search.
What’s next?
The concept-based semantic approach allows us to dig deeper in the specific concepts that brought us to select a specific art unit, thus increasing the transparency of our art unit prediction. By pinpointing differences in the concepts of a specific art unit versus the one of another art unit, we could assist in establishing a semantic strategy in avoiding specific art units. This is where our development strategy will concentrate in the following months.